
[DDD START!] CHAPTER 2. 아키텍처 개요
// TODO : jyjang - 앞부분 TBD
도메인 영역의 주요 구성요소 (p.54)
- entitiy
- 고유의 식별자를 갖는 객체
- 도메인의 고유한 개념을 표현함
- 예시 : Order, Member, Product …
- 도메인 모델의 데이터를 포함하며 해당 데이터와 관련된 기능을 함께 제공
- value
- 고유 식별자를 갖지 않는 객체
- 주로 도메인 객체의 속성을 표현할 때 사용됨
- 예시 : Address, Money …
- entity의 속성으로 사용되거나 다른 value의 속성으로도 사용됨
- aggregate
- 관련된 entitiy와 value 객체를 개념적으로 하나로 묶은 것임
- 예시 : 주문과 관련된 Order 엔티티, OrderLine 밸류, Orderer 밸류 객체를 ‘주문’ 애그리거트로 묶을 수 있음
- repository
- 도메인 모델의 영속성을 처리
- 예시 : DBMS 테이블에서 entity 객체를 로딩하거나 저장하는 기능을 제공
- domain service
- 특정 entitiy에 속하지 않은 도메인 로직을 제공
- 도메인 로직이 여러 entity와 value를 필요로 할 경우 도메인 서비스에서 로직을 구현함
- 예시 : ‘할인 금액 계산’은 상품, 쿠폰, 회원 등급, 구매 금액 등 다양한 조건을 이용하여 구현하기 때문에 도메인 서비스에서 구현해야함
엔티티와 밸류
- 도메인 모델의 엔티티와 DB 모델의 엔티티는 같은 것이 아님!!!
- 두 모델의 차이
- 도메인 모델의 엔티티는 데이터와 함께 도메인 기능을 함께 제공함
- 예시 : 주문을 표현하는 엔티티는 주문 관련 데이터 뿐만 아니라 배송지 주소 변경 기능도 함께 제공함
- 도메인 모델의 엔티티는 두 개 이상의 데이터가 개념적으로 하나인 경우 밸류 타입을 이용해서 표현할 수 있다
- 도메인 모델의 엔티티
- Order에 Orderer 밸류가 속성으로 있는 것이 명확하게 보임
- 도메인 모델의 엔티티
// 도메인 모델 엔티티 public class Order { // ... private Orderer orderer; // ... } // 밸류 public class Orderer { private String name; // ... }- DB 모델의 엔티티
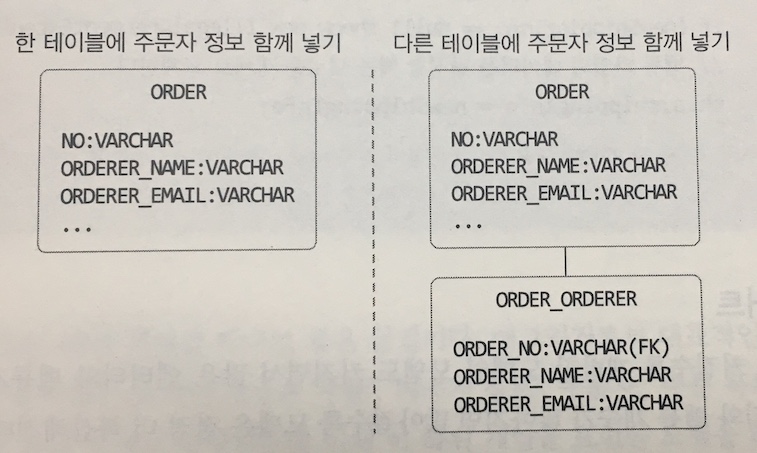
- 왼쪽 케이스는 주문자(Orderer) 라는 개념이 드러나지 않는 단점이 있음
- 오른쪽 케이스는 주문자 데이터를 별도 테이블로 저장했지만 엔티티에 가깝지 밸류 타입의 의미가 드러나지는 않음
- 도메인 모델의 엔티티는 데이터와 함께 도메인 기능을 함께 제공함
- 두 모델의 차이
- 밸류는 불변으로 구현하는 것을 권장함
- 이는 엔티티의 밸류 타입 데이터를 변경할 때는 (기존 객체 값을 변경하는 것이 아니라) 객체 자체를 완전히 교체해야함을 의미함
애그리커트
- 도메인이 커짐 -> 도메인 모델도 커짐 -> 많은 엔티티와 밸류가 출현 -> 모델은 점점 더 복잠해짐
- 도메인 모델이 복잡해지면 개발자는 전체 구조가 아닌 한 개 엔티티와 밸류에만 집중하는 경우가 발생함
- 애그리거트는 이러한 상황을 막고 개발자가 전체 구조를 이해하는데 도움을 줌
- 애그리거트는 관련 객체를 하나로 묶은 군집이다 (자바로 치면 패키지?)
- 관련 객체를 애그리거트로 묶으면 복잡한 도메인 모델을 관리하는데 도움이 됨
- 개별 객체 간의 관계가 아닌 애그리거트 간의 관계로 도메인 모델을 이해하고 구현할 수 있게 됨, 이를 통해 큰 틀에서 도메인 모델을 관리할 수 있게 됨
- root entity : 애그리거트는 군집에 속한 객체들을 관리하는 루트 엔티티를 갖음
- 루트 엔티티는 애그리거트에 속해 있는 엔티티와 밸류 객체를 이용해서 애그리거트가 구현해야할 기능을 제공함
- 애그리커트를 사용하는 코드는 애그리거트 루트가 제공하는 기능을 실행하고 애그리거트 루트를 통해서 간접적으로 애그리거트 내의 다른 앤티티나 밸류 객체에 접근하게됨
리포지터리
- 도메인 객체를 지속적으로 사용하기 위해 DB, File 과 같은 저장소에 보관해야함. 이를 위한 도메인 모델이 리포지터리임
- 엔티티나 밸류는 요구사항에 도출되는 도메인 모델인 반면, 리포지터리는 구현을 위한 도메인 모델임
- 리포지터리를 통해서 도메인 객체를 구한 뒤에 도메인 객체의 기능을 실행하게 됨
- 예시 : 주문 취소
public class CancelOrderService { private OrderRepository orderRepository; public void cancel(OrderNumber number) { Order order = orderRepository.findByNumber(number); // 리포지터리를 통해 도메인 객체를 구함 if (order == null) { throw new NoOrderException(number); } order.cancel(); // 도메인 객체의 기능을 실행 } } -
모듈 구조
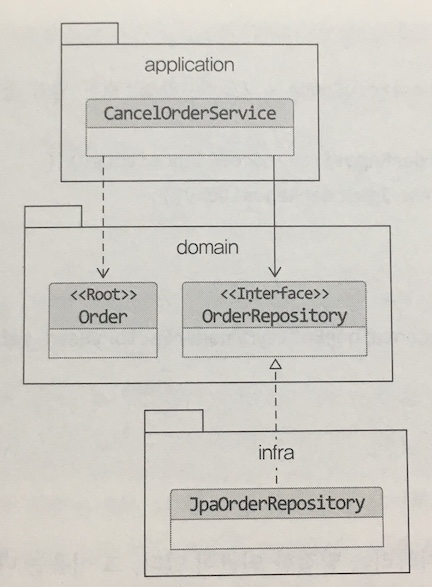
- Repository 인터페이스는 도메인 모델 영역에 속하며, 실제 구현 클래스는 infrastructure 역역에 속함
- 응용 서비스는 의존 주입과 같은 방식을 사용해서 실제 리포지터리 구현 객체에 접근함
- 응용 서비스는 리포지터리와 밀접한 연관이 있는 이유
- 응용 서비스는 필요한 도메인 객체를 구하거나 저장할 때 리포지터를 사용함
- 응용 서비스는 트랜잭션을 관리하는데, 트랜잭션 처리는 리포지터리 구현 기술에 영향을 받음
- 리포지터리의 사용 주체는 응용 서비스임. 따라서 리포지터리는 응용 서비스가 필요로 하는 메소드를 제공함
- 애그리거트를 저장하는 메서드
- 애그리거트 루트 식별자로 애그리거트를 조회하는 메서드
2
public interface SomeRepository { void save(Some some); Some findById(SomeId id); }
요청 처리 흐름 (p.65)
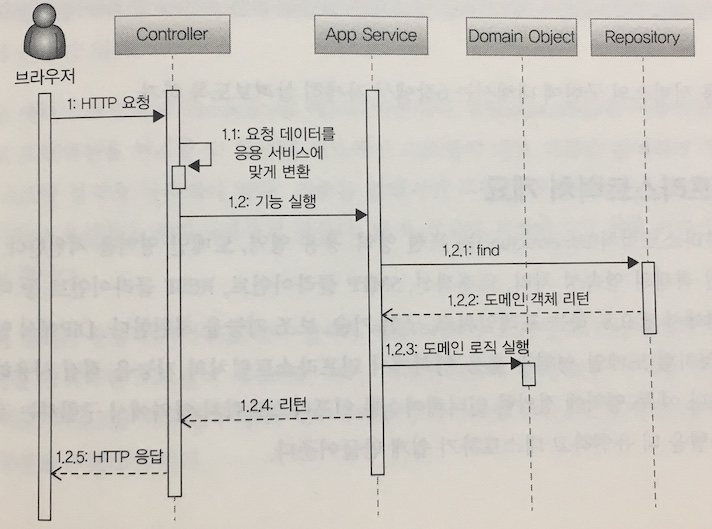
- 사용자 요청 -> 표현 영역에서 받음 (사용자가 전송한 데이터 형식이 올바른지 검사, 응용 서비스에 맞는 형태로 데이터 변환) -> 응용 서비스에 기능 실행을 위임 -> 응용 서비스는 도메인 모델을 이용해서 기능 구현
인프라스트럭처 개요
- 인프라스트럭처는 표현 영역, 응용 영역, 도메인 영역을 지원함
- 도메인 객체의 영속성 처리, 트랜잭션, SMTP 클라이언트, REST 클라이언트 등
- 도메인 영역과 응용 영역에서 인프라스트럭처의 기능을 직접 사용하는 것보다, 이 두 영역에 정의한 인터페이스를 인프라스트럭처 영역에서 구현하는 것이 시스템을 더 유연하고 테스트하기 쉽게 만들어준다.
- 하지만, 무조건 인프라스트럭처에 대한 의존을 없애는 것이 좋은 것은 아님
- 응용 서비스에 트랜젝션 관리를 위한 @Transactional을 추가하거나, 도메인 모델 클래스에 영속성 처리를 위한 JPA @Entity, @Table 같은 것들을 사용하는 것이 편리함
- 구현의 편리함은 DIP가 주는 장점만큼 중요하기 때문에, DIP의 장점을 해치지 않는 범위에서 의존성을 가져가는게 현명함
- 응용 서비스에 트랜젝션 관리를 위한 @Transactional을 추가하거나, 도메인 모델 클래스에 영속성 처리를 위한 JPA @Entity, @Table 같은 것들을 사용하는 것이 편리함
- 표현 영역은 항상 인프라스트럭처 영역과 쌍을 이룸 : 사용 프레임워크에 맞는 방법으로 구현해야함
// TODO : jyjang - TBD
댓글남기기